A1-2 图像分类-kNN算法
课程《Deep Learning for Computer Vision》的作业1-2部分。
基本原理
kNN(k-nearest neighbor)是一种基本的分类方法,是一种监督学习方法。该算法需要带有标签的训练集,对于每一组测试数据,在训练集中寻找与其距离最近的$K$个元素,在分类问题中,这$K$个元素中出现次数最多的标签即为测试数据的标签。
距离可以有不同的度量方法,不同度量方法得到的结果也不同。对于图像数据,它可以用张量表示,通常有曼哈顿距离和欧几里得距离两种度量方法。若$I^p$为张量对应位置的元素,$d_1,d_2$分别为曼哈顿距离,欧几里得距离,则
$$d_1(I_1,I_2)=\sum_p |I_1^p-I_2^p|$$ $$d_2(I_1,I_2)=\sqrt{\sum_p(I_1^p-I_2^p)^2}$$
训练时间复杂度:由于该算法的训练过程只是把数据集保存起来,所以训练复杂度为$O(1)$
测试时间复杂度:对于每一个测试数据,我们要遍历训练集,计算它们之间的距离,所以测试复杂度为$O(N)$
可以看出,该算法训练很快,但实际预测的时候比较慢,这不是我们希望的结果,训练慢一些可以忍受,但实际预测很慢是一个很大的缺陷。
直观理解
假设我们要分类的图像只由两个像素组成,它可以表示为平面直角坐标系中的一个点。平面上不同颜色的区域代表不同的标签,横纵坐标分别表示其两个像素。
当$K$取不同的值时,分类情况不同,如下图
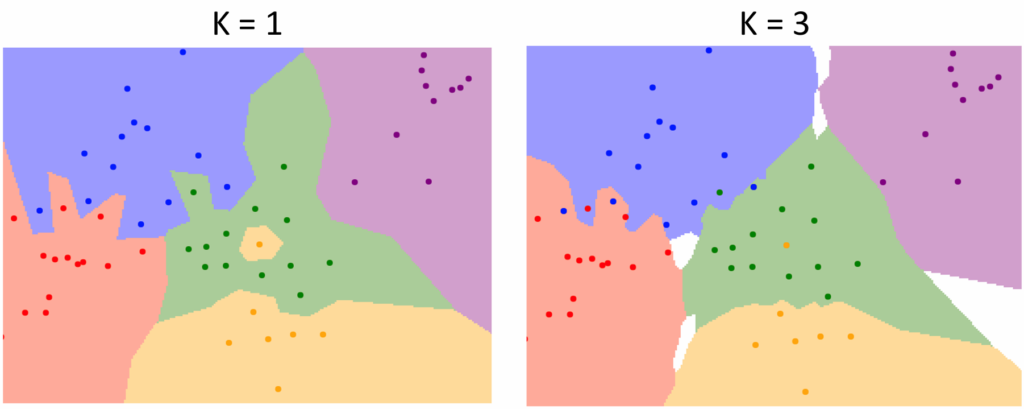
可以看出,$K=1$时不同颜色之间的交界非常曲折,而且还有黄色小区域被包含在绿色区域中的情况,会影响该区域周围点的判断;而$K=3$时分界线更为平滑,但此时不同类之间会出现空位。
当使用的距离定义不同时,分类情况不同,如下图
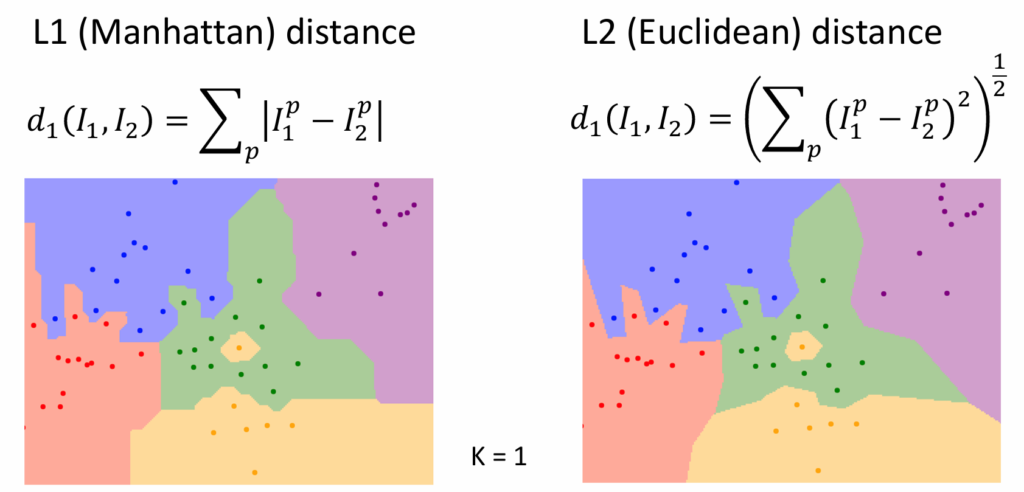
可以看出,当使用曼哈顿距离时,分界线的走向只能是固定角度,而使用欧几里得算法时,分界线的走向可以是任意的。
hyperparameters
从上面我们可以知道,当距离的度量方法或$K$不同时,分类的结果会不同,而这些值不是从训练中得到的,而是在开始之前我们人为设定的,它们会影响分类的结果,被称为hyperparameters,找到适当的值,对于算法的效果可以有显著影响。
参数调整
所以我们需要找到适当的方法来确定hyperparameter的值,基本思路是取那些能让训练结果最好的值。
例如,我们要确定$K$的值,首先,我们不能直接在所有数据上观察结果,因为那样会得到$K=1$,与自己重合准确率永远为100%,用训练集训练,测试集观察结果也是不恰当的,因为测试数据会污染原有的训练结果,无法预知其在新数据上的表现。更好的方法是,把所有数据分为训练集、验证集和测试集。通过验证集的结果取值,只在最后一步使用测试集测试结果,这样我们可以得知其在新数据上的表现。
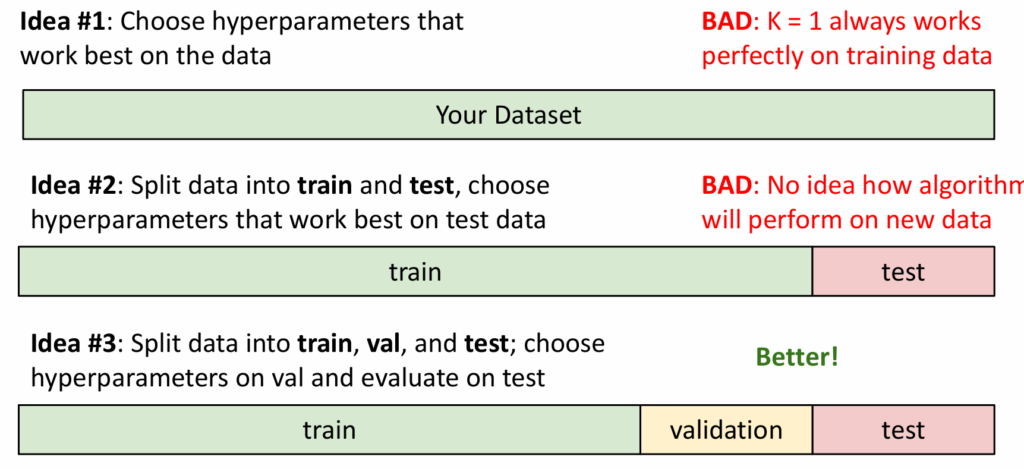
我们也可以把数据分成小块,使用多个验证集。
例如,对于每一个k,计算出平均准确度后,得到类似的图:
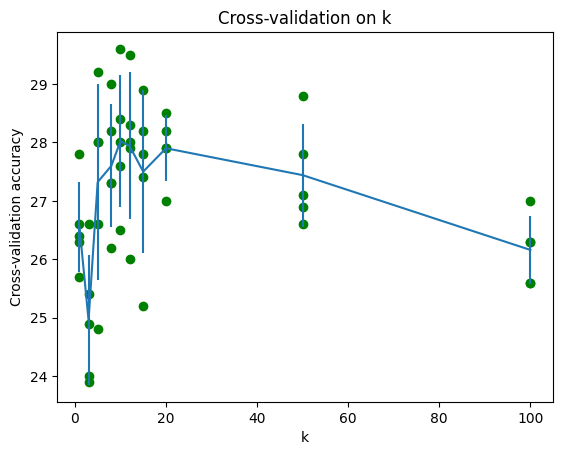
根据数据选出最合适的k值。
缺陷
- 测试时速度很慢
- 仅使用距离度量不能准确把握图像特征,如只对图像做一些简单的旋转,就可能大幅改变原图像的像素值
该算法在有些时候并不能得到很好的结果,但若把距离度量改成提取并比较图像的特征向量的方式,我们可以得到很好的结果。
A2 线性分类器(Linear Classifier)
参考资料:CS231n Convolutional Neural Networks for Visual Recognition
通过一个线性函数将输入映射到类别,即最终会得到每一个类别的“得分”。对于特征向量$\mathbf{x}=[x_1,x_2,…,x_n]$,决策函数为$$f(\mathbf{x})=\mathbf{w}^T\mathbf{x}+b$$
$\mathbf{w}$是权重向量,$b$是偏置量,$f(\mathbf{x})$即为输入在该类别的得分。训练一个分类器的过程,实际上就是通过特定算法找到合适的$\mathbf{w}$和$\mathbf{b}$。
对权重矩阵$W$的理解
从几何角度看,权重矩阵 $W$ 的每一行都是一个“方向指针”,它在高维空间中定义了一个分类决策边界的朝向。这个指针 $w_j$ 指向了模型认为最能代表第 $j$ 类的方向,而分类得分 $s_j=w_j⋅x+b_j$ 就衡量了输入数据 $x$ 在这个方向上的投影强度。因此,训练权重 $W$ 的过程,本质上是在旋转这些决策边界;而训练偏置项 $b$ 则是在平移它们,最终目标是在空间中找到最佳的分割面来区分不同类别的数据。
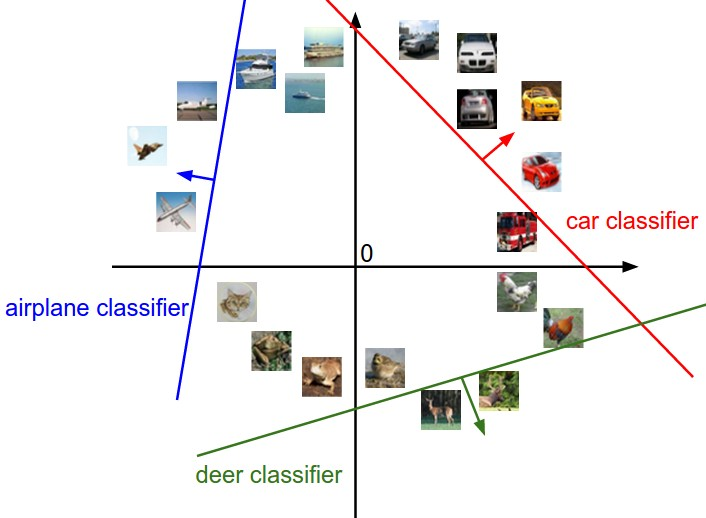
还可以从模板匹配的角度理解,尤其在图像识别中。这里,$W$ 的每一行可以被看作是一个学习到的、对应某个类别的“理想化模板”。分类过程就像是将输入图片与每个类别的模板逐一进行内积运算,以计算“匹配度”,得分最高的模板即为预测类别。这两种视角是统一的:几何空间中那个指向特定方向的“指针”,正是视觉上那个“理想化的模板”。因此,学习权重 $W$ 的最终目的,就是找到一套最完美的模板,能最有效地识别出对应类。

SVM(支持向量机)
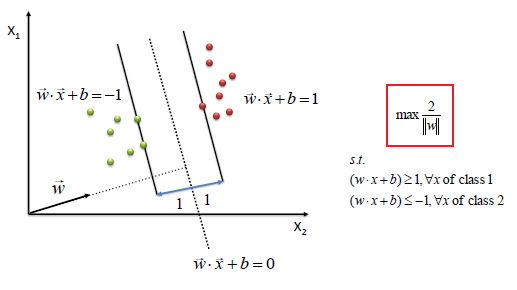
支持向量机算法的思想是要找到一个“超平面”,分开不同的类别。“超平面”实际上就是$\mathbf{w}^T\mathbf{x}+\mathbf{b}=0$,若输入向量是二维的,那它实际上就是一条直线,即在两类数据时间画一条直线,尽可能把它们分开并且直线到两类数据的距离都要尽量远。
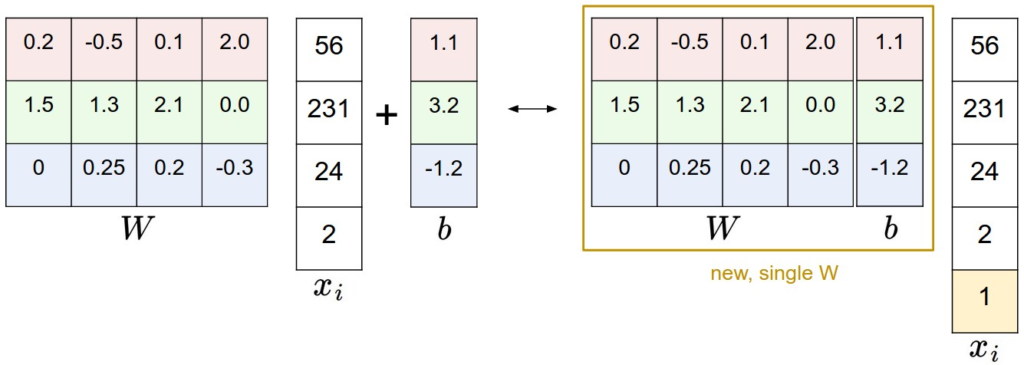
Bias Trick
可以把$\mathbf{b}$整合进$\mathbf{w}$中,只需在输入向量$\mathbf{x}$最后加上值等于1的一维即可达到与原来相同的效果
损失函数(Loss Function)
SVM使用Hinge Loss,多分类问题中,对于第$i$组数据,计算表达式为$$L_i=\sum_{j\neq y_i}max(0, s_j – s_{y_i} + \Delta)$$
$y_i$为该组的正确类别,$j$为类别,$s$为得分,$\Delta$为安全边界,是一个hyperparameter
从上面的表达式我们可以看出,只有当$s_{y_i} – s_j < \Delta$时,才会累加loss,也就是,我们希望正确类别的得分要比其他类别的得分至少高出$\Delta$。
正则化(Regularization)
如果我们只是用上面的损失函数进行训练,机器为了尽可能减小loss,可能会导致某些权重非常大,这样训练出来的模型虽然在训练集上有很好的效果,但在验证集和测试集上效果会很差,这被称为过拟合(overfit)。
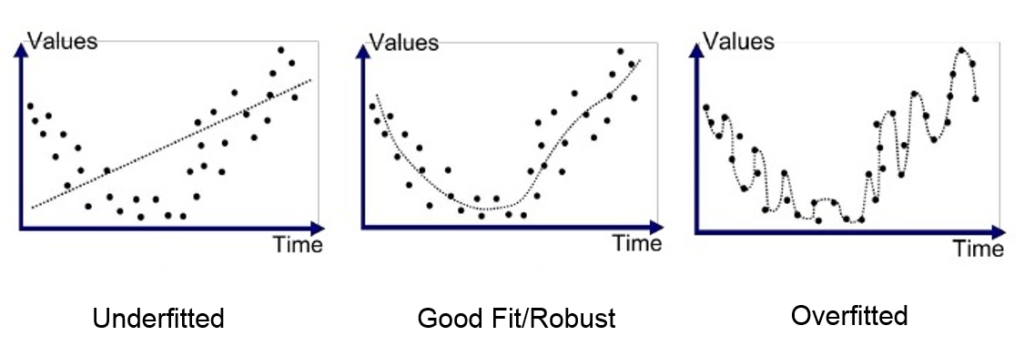
为了避免过拟合,我们可以在loss函数中增加一个量,用来限制模型无限拟合训练集,在拟合程度过高时给出惩罚。L2正则化是常用的方法,其表达式为$$R(W)=\sum_k\sum_l W_{k,l}^2$$即$W$中每一项的平方求和,在出现某一个权重值非常大时,该值会非常大,也就是,这一项能促进$W$向每一个权重均匀分布的方向优化。
最终的损失函数为$$L=\frac{1}{N}\sum_i L_i+\lambda R(W)$$对Hinge Loss求平均值,$\lambda$是正则化强度,用于控制对过拟合的惩罚力度,是一个hyperparameter
把上面的式子展开,得到$$L = \frac{1}{N} \sum_i \sum_{j \neq y_i} \left[ \max(0, f(x_i; W)_j – f(x_i; W)_{y_i} + \Delta) \right] + \lambda \sum_k \sum_l W_{k,l}^2$$其中$f(x_i;W)=Wx_i,f(x_i;W)_j=w_j^Tx_i$,$x_i$为列向量。
我们的目标就是找到让$L$尽可能小的$W$,可以使用梯度下降法。
随机梯度下降(Stochastic Gradient Descent, SGD)
梯度下降就是求$L$对$W$的偏导数(梯度),然后用它来更新$W$,使$W$朝着减小$L$的方向更新。表达式为$$W_{t+1} = W_t – \eta \cdot \nabla_W L_i(W_t)$$其中$\eta$为学习率,用来控制每一步移动多少,是一个hyperparameter,$\nabla_W L_i(W_t)$就是$L$对$W$中每个元素的偏导数,形状与$W$相同。
随机梯度下降就是每次随机选择一个小样本来计算梯度并更新$W$,对于大数据集来说更高效。
梯度计算
多分类支持向量机(SVM)的核心思想是最大化间隔(Maximizing Margin)。对于一个样本,模型对正确类别的打分,应该比对任何一个错误类别的打分至少高出一个预设的安全边际 $\Delta$。如果这个条件未满足,模型就会产生损失。
基于此思想,对于单个样本 $i$,其损失 $L_i$ 定义如下(我们设安全边际 $\Delta = 1$):
$$L_i = \sum_{j \neq y_i} \max(0, s_j – s_{y_i} + 1)$$
这里 $s_j$ 是模型对错误类别 $j$ 的打分,$s_{y_i}$ 是模型对正确类别 $y_i$ 的打分。
我们的目标是计算这个损失 $L_i$ 相对于模型直接输出的每一个分数 $s_k$ 的偏导数(梯度),即 $\frac{\partial L_i}{\partial s_k}$。
首先,我们计算相对于错误类别分数 $s_k$(即 $k \neq y_i$)的梯度。在此情况下,分数 $s_k$ 只出现在损失函数求和式中 $j=k$ 的那一项里。因此,我们只需求导这一项:
$$\frac{\partial L_i}{\partial s_k} = \frac{\partial}{\partial s_k} \max(0, s_k – s_{y_i} + 1)$$
根据 $\max(0, x)$ 函数的求导规则,如果括号内的项 $s_k – s_{y_i} + 1 > 0$(即安全边际被“侵犯”),则导数为 1;反之,如果 $s_k – s_{y_i} + 1 \le 0$(即满足安全边际),则导数为 0。
接下来,我们计算相对于正确类别分数 $s_{y_i}$ 的梯度。这次,分数 $s_{y_i}$ 出现在求和的每一项中,所以我们需要对整个求和式求导:
$$\frac{\partial L_i}{\partial s_{y_i}} = \frac{\partial}{\partial s_{y_i}} \sum_{j \neq y_i} \max(0, s_j – s_{y_i} + 1) = \sum_{j \neq y_i} \frac{\partial}{\partial s_{y_i}} \max(0, s_j – s_{y_i} + 1)$$
对于求和中的每一项,如果其内容 $s_j – s_{y_i} + 1 > 0$,则该项对 $s_{y_i}$ 的导数是 -1;否则导数为 0。因此,总梯度是所有这些 -1 的总和,也就是“侵犯了安全边际的错误类别的数量”的负值。
综上所述,对于一个样本,损失 $L_i$ 对分数向量 $s$ 的梯度可以这样得到:首先初始化一个全为0的梯度向量,然后遍历所有错误类别 $j$。如果某个错误类别 $j$ 侵犯了安全边际(即 $s_j – s_{y_i} + 1 > 0$),那么梯度向量中第 $j$ 个元素的值就设为 1,同时将第 $y_i$ 个元素(对应正确类别)的值减1。
Softmax
Softmax是一个激活函数,可以把输出的分数转换为概率分布,表达式为$$\sigma(\mathbf{z})_j = \frac{e^{z_j}}{\sum_{k=1}^{C} e^{z_k}}$$$\mathbf{z}$为上面提到的每一类的分数,$z_j$为第$j$类的分数。
可以看出,$\sigma(\mathbf{z})_j \in (0,1) \quad $且$ \quad \sum_{j=1}^{C} \sigma(\mathbf{z})_j = 1$,所以这可以理解成是第$j$类的概率,使用指数的形式,可以放大最大值的优势。
交叉熵损失(Cross-Entropy Loss)
交叉熵损失源于信息论,它用于衡量两个概率分布之间的差异。在多分类问题中,这两个分布是:
- 预测分布 (Predicted Distribution):这是 Softmax 函数输出的概率向量。
- 真实分布 (True Distribution):这是一个 one-hot 编码的向量,正确类别的概率为 1,其他所有类别的概率都为 0。
交叉熵损失的通用数学公式为:$$H(p, q) = – \sum_{i} p(x_i) \log(q(x_i))$$
其中$p(x_i)$ 代表事件 $x_i$ 的真实概率(在机器学习分类任务中,这通常是 one-hot 编码后的标签,正确类别为1,其余为0)。$q(x_i)$ 代表模型预测事件 $x_i$ 发生的概率。
在多分类任务中,Softmax常与交叉熵损失结合使用,即第$i$组数据损失函数为$$L_i=-log(\frac{e^{s_{y_i}}}{\sum_{j}e^{s_{j}}})$$
令$p_i=\frac{e^{s_{y_i}}}{\sum_{j}e^{s_{j}}}$,并加入L2正则化,总的损失函数$$L=-\frac{1}{N}\sum_i log(p_i)+\lambda R(W)$$我们需要最大化正确类别的概率,即最小化$L$,也可以使用梯度下降法来完成。
数值稳定性(Numeric stability)
Softmax中当输入的$x$比较大时,$e^x$会非常大,很容易导致上溢,造成计算结果不稳定。由于Softmax 的输出只依赖于输入分数的相对差异,不依赖于其绝对值,所以,可以对所有分数进行平移(同加/减一个常数),而最终概率不变。即$$ \text{softmax}(z)_i = \frac{e^{z_i}}{\sum_j e^{z_j}} = \frac{e^{z_i – C}}{\sum_j e^{z_j – C}} $$在实际应用中,我们通常把输入分数向量$\mathbf{z}$中的每个元素减去$\mathbf{z}$中的最大值,使最大值变为0,其他值变为负数,避免了上溢的问题。
梯度计算
首先定义推导中需要用到的符号:
- $C$: 类别总数。
- $z$: 神经网络最后一层的原始输出,也称为 logits。这是一个包含 $C$ 个元素的向量,$z = [z_1, z_2, …, z_C]$。
- $a$: 经过 Softmax 函数处理后的输出,代表模型预测的每个类别的概率。$a = [a_1, a_2, …, a_C]$。
- $y$: 真实的标签,采用 one-hot 编码。$y = [y_1, y_2, …, y_C]$。
- $L$: 最终的交叉熵损失。
接下来是两个核心的函数公式。
Softmax 函数的公式为:
$$a_j = \text{softmax}(z)_j = \frac{e^{z_j}}{\sum_{k=1}^{C} e^{z_k}}$$
交叉熵损失函数 (Cross-Entropy Loss) 的公式为:
$$L = -\sum_{i=1}^{C} y_i \log(a_i)$$
由于$y$是one-hot编码,所以$L$实际上只有一项不为0。
我们的目标是计算损失 $L$ 相对于 logits $z_j$ 的梯度(偏导数),即 $\frac{\partial L} {\partial z_j}$。
根据链式法则(由于$z$中任意一个数的值改变会影响$a$中的所有值,所以需要对$a$中每一个值求偏导),我们可以将梯度计算展开为:
$$\frac{\partial L}{\partial z_j} = \sum_{i=1}^{C} \frac{\partial L}{\partial a_i} \frac{\partial a_i}{\partial z_j}$$
第一步,计算 $\frac{\partial L} {\partial a_i}$:
$$\frac{\partial L}{\partial a_i} = \frac{\partial}{\partial a_i} \left( -\sum_{k=1}^{C} y_k \log(a_k) \right) = -y_i \frac{1}{a_i} = -\frac{y_i}{a_i}$$
第二步,计算 $\frac{\partial a_i} {\partial z_j}$。这里需要分两种情况:
情况 A: 当 $i = j$ 时
对 $a_i$ 关于 $z_i$ 求导,使用除法求导法则:
$$\frac{\partial a_i}{\partial z_i} = \frac{e^{z_i} \left( \sum_{k=1}^{C} e^{z_k} \right) – e^{z_i} e^{z_i}}{\left( \sum_{k=1}^{C} e^{z_k} \right)^2} = \frac{e^{z_i}}{\sum_{k=1}^{C} e^{z_k}} – \left( \frac{e^{z_i}}{\sum_{k=1}^{C} e^{z_k}} \right) \left( \frac{e^{z_i}}{\sum_{k=1}^{C} e^{z_k}} \right) = a_i – a_i^2 = a_i(1 – a_i)$$
情况 B: 当 $i \neq j$ 时
对 $a_i$ 关于 $z_j$ 求导:
$$\frac{\partial a_i}{\partial z_j} = \frac{0 \cdot \left( \sum_{k=1}^{C} e^{z_k} \right) – e^{z_i} e^{z_j}}{\left( \sum_{k=1}^{C} e^{z_k} \right)^2} = -\left( \frac{e^{z_i}}{\sum_{k=1}^{C} e^{z_k}} \right) \left( \frac{e^{z_j}}{\sum_{k=1}^{C} e^{z_k}} \right) = -a_i a_j$$
现在,将以上结果代回链式法则的公式中。我们将求和拆分为 $i=j$ 和 $i \neq j$ 两部分:
$$\frac{\partial L}{\partial z_j} = \left( \frac{\partial L}{\partial a_j} \frac{\partial a_j}{\partial z_j} \right) + \sum_{i \neq j} \left( \frac{\partial L}{\partial a_i} \frac{\partial a_i}{\partial z_j} \right)$$
代入具体导数值:
$$= \left( -\frac{y_j}{a_j} \right) \cdot \left( a_j(1 – a_j) \right) + \sum_{i \neq j} \left( -\frac{y_i}{a_i} \right) \cdot \left( -a_i a_j \right)$$
化简得到:
$$= -y_j(1 – a_j) + \sum_{i \neq j} y_i a_j$$
展开并提取公因数 $a_j$:
$$= -y_j + y_j a_j + a_j \sum_{i \neq j} y_i$$
因为 $y$ 是 one-hot 向量, $\sum y_i = 1$,所以 $\sum_{i \neq j} y_i = 1 – y_j$。代入上式:
$$= -y_j + y_j a_j + a_j (1 – y_j)$$
$$= -y_j + y_j a_j + a_j – a_j y_j$$
消去中间两项,最终得到一个非常简洁的结果:
$$\frac{\partial L}{\partial z_j} = a_j – y_j$$
这个结果意味着,损失函数对神经网络原始输出(logits)的梯度,就等于模型预测的概率向量与真实标签的 one-hot 向量之差。可以看到,在softmax和交叉熵损失同时使用时,损失函数的梯度非常简单,所以这是一种很常用的方法。